- Generative AI - Home
- Generative AI Basics
- Generative AI Basics
- Generative AI Evolution
- ML and Generative AI
- Generative AI Models
- Discriminative vs Generative Models
- Types of Gen AI Models
- Probability Distribution
- Probability Density Functions
- Maximum Likelihood Estimation
- Generative AI Networks
- How GANs Work?
- GAN - Architecture
- Conditional GANs
- StyleGAN and CycleGAN
- Training a GAN
- GAN Applications
- Generative AI Transformer
- Transformers in Gen AI
- Architecture of Transformers in Gen AI
- Input Embeddings in Transformers
- Multi-Head Attention
- Positional Encoding
- Feed Forward Neural Network
- Residual Connections in Transformers
- Generative AI Autoencoders
- Autoencoders in Gen AI
- Autoencoders Types and Applications
- Implement Autoencoders Using Python
- Variational Autoencoders
- Generative AI and ChatGPT
- A Generative AI Model
- Generative AI Miscellaneous
- Gen AI for Manufacturing
- Gen AI for Developers
- Gen AI for Cybersecurity
- Gen AI for Software Testing
- Gen AI for Marketing
- Gen AI for Educators
- Gen AI for Healthcare
- Gen AI for Students
- Gen AI for Industry
- Gen AI for Movies
- Gen AI for Music
- Gen AI for Cooking
- Gen AI for Media
- Gen AI for Communications
- Gen AI for Photography
Autoencoders in Generative AI
Autoencoders are an essential tool in the field of machine learning and deep learning. They are a special type of unsupervised feedforward neural network designed to learn efficient representations of the data for the purpose of dimensionality reduction, feature extraction, and generating new data.
Autoencoders consists of two components an encoder network and a decoder network. The encoder network works as a compression unit that compresses the input data into a lower-dimensional representation. On the other hand, the decoder network decompresses the compressed input data by reconstructing it. Read this chapter to understand about Autoencoders, its architecture, working, training process and hyperparameter tuning.
What are Autoencoders?
Autoencoders, designed for unsupervised learning, are a class of artificial neural networks. Like any other neural network, it consists of three different types of layers-Input, hidden and output. The number of input units in the input layer are exactly equal to the output units in the output layer. But the middle layer, i.e., the hidden layer in this network has a fewer number of units than that of input and output layers.
It first compresses the input data into a lower-dimensional representation. As the hidden layer has a lower number of units, it holds this lower-dimensional representations. Finally, at the output layer, the output is rebuilt from this reduced representation of the input.
Autoencoders are also called self-supervised ML models because they are trained as supervised ML models but while using, they work as unsupervised ML models.
Architecture of Autoencoders
The core architecture of an autoencoders is divided into encoder, decoder and bottleneck layer as shown in the below diagram −
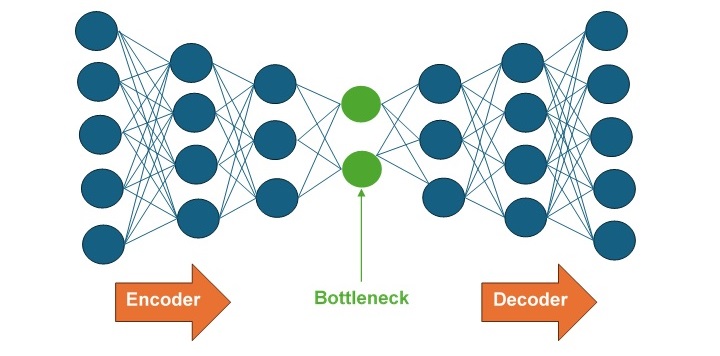
- Encoder − Encoder is a fully connected feed forward neural network (FFNN) that compresses the input data into a lower-dimensional representation.
- Bottleneck layer − The bottleneck layer contains the lower-dimensional representation of the input which is to be fed into the decoder.
- Decoder − Decoder is a fully connected feed forward neural network (FFNN) that reconstruct the input back to the original dimensions.
How Do Autoencoders Work?
The principle behind the working of an autoencoders is to train the neural network to reconstruct its input data from a lower-dimensional representation. This involves two main components: the encoder network and the decoder network.
The Encoder Network
The encoder network compresses the input into a lower-dimensional representation. This process involves the following steps −
- Input Layer − The input data is fed into the network through input layer.
- Hidden Layes − The input data now passes through several hidden layers where each layer first applies a linear transformation and then a non-linear activation function. Each layer has fewer neurons than the previous one which gradually reduces the dimensionality of the input data.
- Bottleneck Layer (Latent Space Representation) − Bottleneck layer, the final layer of the encoder network, stores the compressed representation of the input. This layer helps the network to learn the most essential features of the input because it has a much lower dimensionality than the input data.
The Decoder Network
The decoder network reconstructs reconstruct the original input data from the lower-dimensional representation. This process is basically the reverse of the encoding process. It involves the following steps −
- Bottleneck Layer (Latent Space Representation) − The compressed data stored by the bottleneck layer is used as the input for the decoder network.
- Hidden Layes − The input data now passes through several hidden layers where each layer first applies a linear transformation and then a non-linear activation function. Each layer has more neurons than the previous one which gradually expanding the dimensionality of the input data back to the original input size.
- Output Layer − Output layer, the final layer of the decoder network, reconstructs the data to match the original input dimensions.
The Training Process
The training process of network to reconstruct its input data from a lower-dimensional representation involves the steps given below −
- Initialization − First the weights of the network are initialized randomly.
- Forward Propagation − In this step the input data is first passed through the encoder to convert it into lower dimensions and then passed through the decoder to reconstruct the input as original.
- Loss Calculation − The loss function is used to measure the difference between the original input data and its reconstructed output. Some of the common loss functions are Mean Squared Error (MSE) for continuous data or Binary Cross-Entropy for binary data.
- Backward Propagation − In this step, to minimize the loss function, the network adjusts its weights. You can use gradient descent or any other optimization algorithm.
Hyperparameter Tuning
Hyperparameter tuning in autoencoder is the process of selecting the best set of parameters that control how an autoencoder work. Proper hyperparameter tuning can improve the efficiency and accuracy of an autoencoder.
Listed below are a set of key hyperparameters to be considered −
- Learning Rate − It determines the step size while using the optimization algorithm for minimizing the loss function. A higher learning rate can lead to faster convergence but with less stability. On the other hand, lower learning can lead to slow convergence but with more stability.
- Batch Size − It specifies the number of training examples utilized per iteration. Larger batch size can provide more accurate estimate of the gradient but require more memory and computational resources.
- Number of Layers − It specify the depth of the autoencoder architecture. More number of layers can capture more complex features, but they may lead to overfitting.
- Number of Neurons per Layer − It determines the number of units in each layer. More number of neurons per layer can learn more details but it increases the complexity of the model.
- Activation Functions − These are the mathematical functions applied to the outputs of each layer. Different activation functions (like ReLU, Sigmoid, Tanh) can affect the performance of model.
Conclusion
Autoencoders compress the input data into a lower-dimensional representation and then the output is rebuilt from this reduced representation of the input. We have discussed how autoencoder works along with its architecture. Understanding the architecture of autoencoder and its working principal, machine learning practitioners can unlock new possibilities in data analysis and enhance model performance.
We have also discussed hyperparameter tuning in autoencoders. Some of the key hyperparameters are learning rate, batch size, number of layers, number of neurons per layer, and activation function. Tuning of these hyperparameters can affect the efficiency and accuracy of the autoencoder.