- Generative AI - Home
- Generative AI Basics
- Generative AI Basics
- Generative AI Evolution
- ML and Generative AI
- Generative AI Models
- Discriminative vs Generative Models
- Types of Gen AI Models
- Probability Distribution
- Probability Density Functions
- Maximum Likelihood Estimation
- Generative AI Networks
- How GANs Work?
- GAN - Architecture
- Conditional GANs
- StyleGAN and CycleGAN
- Training a GAN
- GAN Applications
- Generative AI Transformer
- Transformers in Gen AI
- Architecture of Transformers in Gen AI
- Input Embeddings in Transformers
- Multi-Head Attention
- Positional Encoding
- Feed Forward Neural Network
- Residual Connections in Transformers
- Generative AI Autoencoders
- Autoencoders in Gen AI
- Autoencoders Types and Applications
- Implement Autoencoders Using Python
- Variational Autoencoders
- Generative AI and ChatGPT
- A Generative AI Model
- Generative AI Miscellaneous
- Gen AI for Manufacturing
- Gen AI for Developers
- Gen AI for Cybersecurity
- Gen AI for Software Testing
- Gen AI for Marketing
- Gen AI for Educators
- Gen AI for Healthcare
- Gen AI for Students
- Gen AI for Industry
- Gen AI for Movies
- Gen AI for Music
- Gen AI for Cooking
- Gen AI for Media
- Gen AI for Communications
- Gen AI for Photography
Feed Forward Neural Network in Transformers
The Transformer model has transformed the field of natural language processing (NLP) as well as other sequence-based tasks. As we discussed in previous chapters, Transformer relies mainly on the multi-head attention and self-attention mechanisms but there is another critical component that equally contributes to the success of this model. This critical component is the Feed Forward Neural Network (FFNN).
The FFNN sub-layer helps the Transformer capture complex patterns and relationships within the input data sequence. Read this chapter to understand the FFNN sublayer, its role in Transformer, and how to implement FFNN in Transformer architecture using Python programming language.
Feed Forward Neural Network (FFNN) Sub-layer
In the Transformer architecture, the FFNN sublayer is just above the multi-head attention sublayer. Its input is the $\mathrm{d_{model} \: = \: 15}$ output of the post layer normalization of the previous layer. FFNN is a simple but powerful component of the Transformer that operates independently on each position of the sequence.
In the following diagram, which is the encoder stack of the Transformer architecture, you can see the position of the FFNN sublayer (highlighted using black circle) −
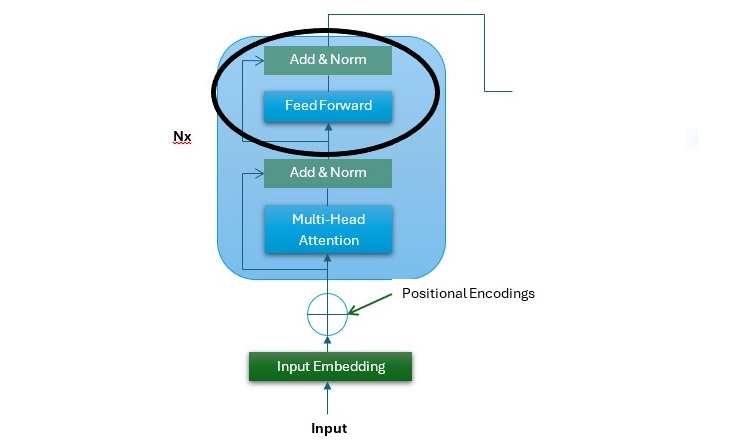
The following points describe the FFNN sublayer −
- The FFNN sublayer in the encoder and decoder of the Transformer architecture is fully connected.
- The FFNN is a position-wise network in which each position is processed separately but in a similar way.
- The FFNN contains two linear transformations and applies an activation function in between them. One of the most common activation functions is ReLU.
- Both the input and output of the FFNN sublayer is $\mathrm{d_{model} \: = \: 512}$.
- In comparison to the input and output layers, the inner layer of the FFNN sublayer is larger with $\mathrm{d_{ff} \: = \: 2048}$.
Mathematical Representation of FFNN Sublayer
The FFNN sublayer can be mathematically represented as below −
First Linear Transformation
$$\mathrm{X_{1} \: = \: XW_{1} \: + \: b_{1}}$$
Here, X is the input to the FFNN sub-layer. $\mathrm{W_{1}}$ is the weight matrix for the first linear transformation and $\mathrm{b_{1}}$ is the bias vector.
ReLU Activation Function
The ReLU activation function enables the network to learn complex pattern by introducing the non-linearity in the network.
$$\mathrm{X_{2} \: = \: max(0, X_{1})}$$
Second Linear Transformation
$$\mathrm{Output \: = \: X_{2}W_{2} \: + \: b_{2}}$$
Here, $\mathrm{W_{2}}$ is the weight matrix for the second linear transformation and $\mathrm{b_{2}}$ is the bias vector.
Lets combine the above steps to summarize the FFNN sub-layer −
$$\mathrm{Output \: = \: max(0, XW_{1} \: + \: b_{1})W_{2} \: + \: b_{2}}$$
Importance of FFNN Sublayer in Transformer
Given below is the role and importance of the FFNN sublayer in the Transformer −
Feature Transformation
The FFNN sub-layer performs complex transformations on the input data sequence. With the help of it model learns detailed and advanced features from the data sequence.
Position-wise Independence
As we discussed in the previous chapter, the self-attention mechanism examines relationships between various positions in the input data sequence. But, on the other hand, the FFNN sub-layer works independently on each position in the input data sequence. This feature enhances the representations generated by the multi-head attention sublayer.
Python Implementation of Feed Forward Neural Network
Given below is a step-by-step python implementation guide that demonstrate how we can implement the Feed Forward Neural Network sub-layer within the Transformer architecture −
Step 1: Initializing Parameters for FFNN
In the Transformer architecture, the FFNN sublayer consists of two linear transformations along with a ReLU activation function in between them. In this step, well initialize the weight matrices and bias vector for these transformations −
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
Step 2: Creating Example Input Data
In this step, we will create some examples input data to pass through our FFNN. In the Transformer architecture, inputs are typically tensors of shape (batch_size, seq_len, d_model).
# Example input dimensions batch_size = 64 # Number of sequences in a batch seq_len = 10 # Length of each sequence d_model = 512 # Dimensionality of the model (input/output dimension) # Random input tensor with shape (batch_size, seq_len, d_model) x = np.random.rand(batch_size, seq_len, d_model)
Step 3: Instantiating and Using the FFNN
Finally, we will instantiate the FeedForwardNN class and perform a forward pass with the above example input tensor −
# Create FFNN instance
ffnn = FeedForwardNN(d_model, d_ff=2048) # Set d_ff as desired dimensionality for inner layer
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
Complete Implementation Example
Combine the above three steps to get the complete implementation example −
# Step 1 - Initializing Parameters for FFNN
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
# Step 2 - Creating Example Input Data
# Example input dimensions
batch_size = 64 # Number of sequences in a batch
seq_len = 10 # Length of each sequence
d_model = 512 # Dimensionality of the model (input/output dimension)
# Random input tensor with shape (batch_size, seq_len, d_model)
x = np.random.rand(batch_size, seq_len, d_model)
# Step 3 - Instantiating and Using the FFNN
# Create FFNN instance
# Set d_ff as desired dimensionality for inner layer
ffnn = FeedForwardNN(d_model, d_ff=2048)
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
Output
After running the above script, it should print the shape of the output tensor to verify the computation −
Output shape: (64, 10, 512)
Conclusion
The Feed Forward Neural Network (FFNN) sublayer is an essential component within the Transformer architecture. It enhances the models ability to capture complex patterns and relationships in input data sequence.
FFNN complements the self-attention mechanism by applying position-wise transformations independently. This makes Transformer a powerful model for natural language processing and other sequence-based tasks.
In this chapter, we have provided a comprehensive overview of the FFNN sublayer, its role and importance in Transformer, and a step-by-step guide showing Python implementation of FFNN in Transformer. Like multi-head attention mechanism, understanding and using FFNN is also important for fully utilizing Transformer models in NLP applications.